Distance Analysis Projects
- Project Started: August 12th 2016
- Last Worked on Version: 1.3.0
- Node.js
- PG & PG Native
- Async.js
- PostgreSQL
- PostGIS
- PostgreSQL Routing
About
Last year I built a spatial analysis toolset based upon road network routing between services and Irish households. The toolset takes a list of destination services such as GP offices, Hospitals, Health Centres or indeed any location with a known X/Y grid reference. It then calculates the distance by road network (according to Ordnance Survey Ireland) between each residential address (given by an Post GeoDirectory) and the nominated service.
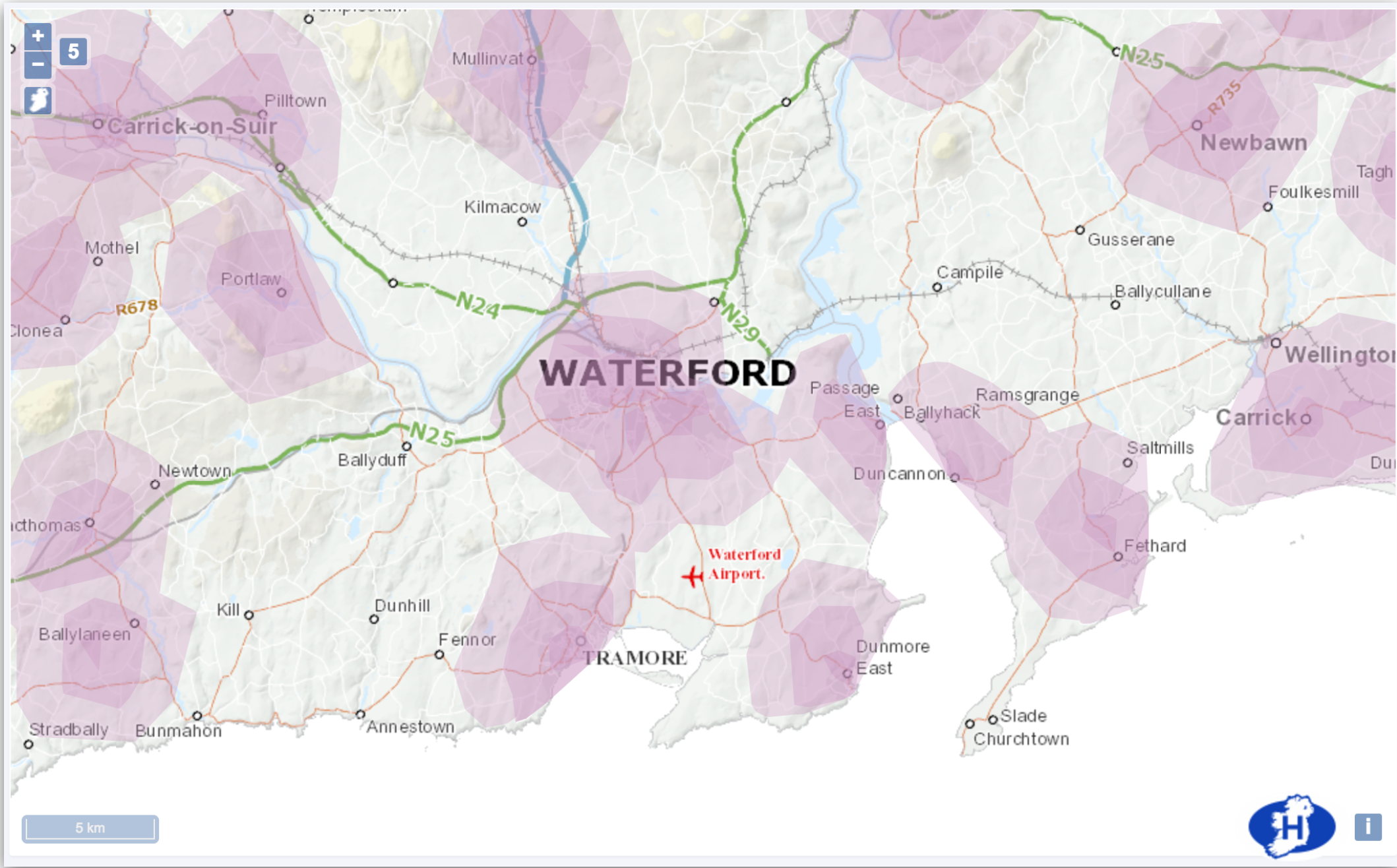
The resulting analysis can be used to determine coverage of a service within a given distance such as GP catchments within 5, 10 and 15Km of Waterford City as pictured above.
Methodology
The spatial abilities of PostgreSQL combined with the PG-Routing add-on, allow for complex routing analyses between points to be run using various algorithms like A-Star and Dijkstra. To take advantage of these, I took the OSI road network of Ireland which was provided in vector format and converted it into a format suitable for routing queries. This also involved the removal of 1000’s of small laneways, bog trails and road fragments that did not connect to the main network which are illustrated below.

Having a routable network, I wrote a number of SQL queries for translating grid coordinates to node ids as well as wrappers around the core routing functions. A distance query between two points took on average 4 seconds to complete. Restricting the network to a given bound box resulted in a large increase in performance but would fail when the required route fell outside the bounding box.
There are approximately 2.3 million residential addresses in Ireland. As some are located within the same building (for example apartment blocks), we can shorten this list to 1.7 million unique residential points in the GeoDirectory database. To complete a full routing query from each one of these address points to just one destination point sequentially would take upwards of 20 days to complete (at 1 query/second). For different projects, the number of destination points could easily be in the thousands, so I decided to use Node.js, the cluster module and the async library to improve performance by developing a universal routing application. This application would take as input, a CSV file of destination grid points and a unique id for each. As output, a set of CSV files containing each source id and grid reference would be returned with the road distance to the closest 5 destination ids present for each entry.
Query Scaling with Node.js
The routing application firstly counts the number of available CPUs on the host machine. It then counts the number of destination points for this project and divides them among the available CPUs. It then forks n CPU times, passing a set amount of work to each of the children. Each child process is then responsible for completing its share of the work load. To avoid the overhead involved in synchronising results back to the parent, each child separately writes to its own CSV output file which gets recombined later.
To improve the query time, the linear distance between the source address and 20 closest destinations is run first. Then, the road distance query is run between this subset and the source address, vastly reducing the number of routing operations required. To further improve the query time, an opportunistic bound box is used, taking the bounding box of four times the distance between source and destination as a suitable limit. If the routing query fails, it is run again without the bounding box limitation to ensure a result is returned if possible.
To monitor progress, each child process uses a Slack integration to report when certain sections of the work are complete or if an error occurred. On a 24 CPU machine with 32GB or RAM, a full 2,200 destination analysis can be completed within 12 hours.
Technical Challenges
While the routing engine can fork a number of processes to complete a given project, each child process must share the same PostgreSQL database server. Using the default configuration, the database would reach the maximum number of clients within moments. It took a week of tuning various parameters to arrive at a working configuration.
While most routing queries return successfully, a small number of them failed, prompting an investigation. The failed source addresses were found to be on various islands on the west coast. While the linear distance query could reach destinations on the mainland, the road network was not connected to the islands resulting in failed queries.
A similar edge case occurs around Western headlands where linear distances will return destination points across a bay. The road network connecting those destinations may not be the shortest path resulting in failed routing queries if the bound box is too small.
GP Catchments
The first project to use this routing engine attempted to find the number of people who live within a certain distance of a GP office in urban areas. Using this information, the project aimed to build a catchment area for each GP office and determine the demographics for each to decide on funding goals for the coming year. For example, GP offices which deal with more disadvantaged people may require more funding than those with a more privileged patient list.
Hospital Catchments
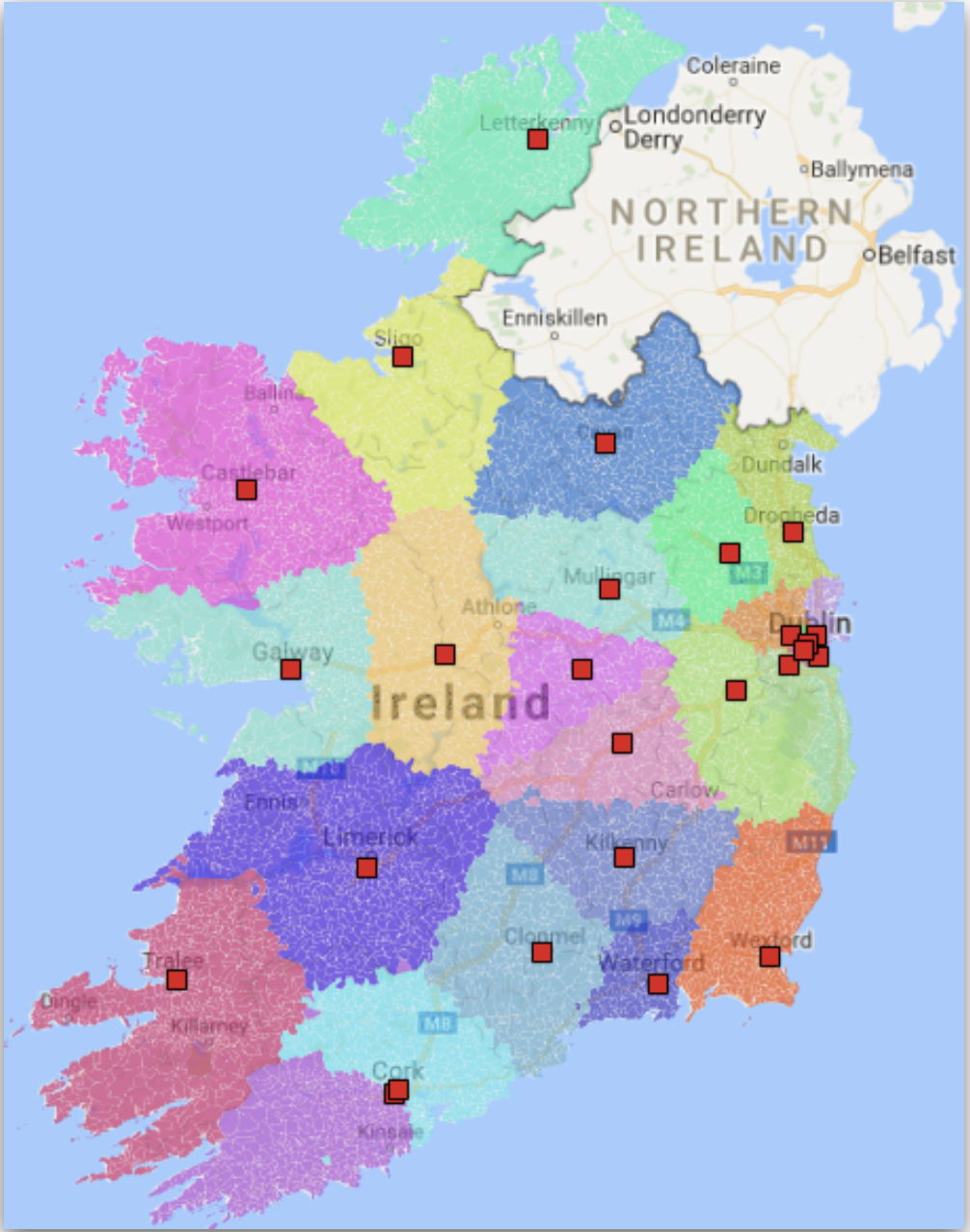
To help define patient catchments for each hospital, a routing analysis was run using the small area centroid as the source point. Each General Acute hospital was listed as a destination and once the routing was complete, each hospital could then be assigned to each small area.
Grouping the areas allowed for geographic catchments to be drawn around each hospital which could be used for further analysis. An example of the catchments is shown below, with each hospital shown as a red square.